



5G信号処理におけるベースバンドユニットの主要機能
リアルタイム信号処理:5Gネットワークで10ミリ秒以下の遅延を実現
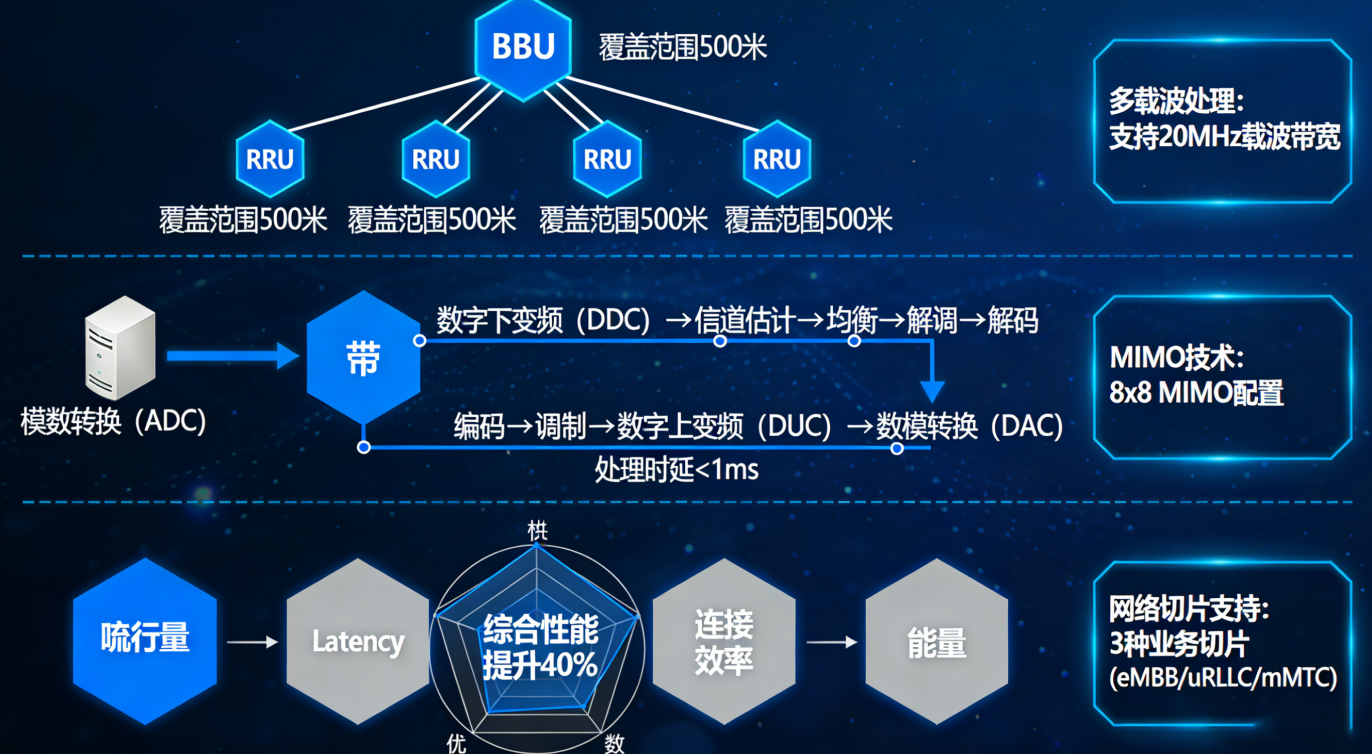
基地局ベースバンドユニット(BBU)は、自律走行車や工場の自動化システムなど、5Gアプリケーションで必要とされる非常に高速な応答時間を実現するために不可欠な、厳密な時間枠内で行われる重要なデジタル信号処理タスクを処理します。これらのユニットは物理層処理を2ミリ秒未満で完了し、信号の往復遅延を3GPP規格が定める10ミリ秒以下の制限内に保ちます。並列処理や専用ハードウェアによるアクセラレーションなどの技術により、BBUは状況の変化に応じてリソース使用量をリアルタイムで動的に調整できます。これにより、ラッシュアワー時や大規模イベント中にネットワークが非常に混雑しても、安定した動作を維持できます。
デジタル信号パイプライン:変調、チャネル符号化、MIMOプリコーディング
BBUのデジタル信号パイプラインは、信号の完全性と周波数利用効率を最大化するために、3つの主要機能を統合しています。
- 調節 qAM-256やQAM-1024といった高次数方式を用いて、データを高密度な無線波形に変換する
- チャネル符号化 lDPCおよびPolar符号を用いることで、4GのTurbo符号と比較してビット誤り率を最大68%低減します
-
MIMOプリコーディング スマートビームステアリングを実現し、周波数効率を3.1倍向上(Mobile Experts 2023)
これらの一連のプロセスにより、人口密集型都市環境におけるパケット損失が最小限に抑えられ、高いスループットが維持されます。
ケーススタディ:トップクラスのBBUが都市部の5G展開において上り遅延を42%削減
2023年に東京で実施された主要メーカーのBBU 6630によるフィールドトライアルでは、仮想化と機械学習によるトラフィック予測によって顕著な性能向上が実証されました。このシステムは以下の成果を達成しました。
- 平均上り遅延を42%削減 (9.2msから5.3msへ)
- セルエッジスループットが17%改善
-
切断される接続が31%減少 引渡し時
これらの結果は、特に高密度の都市部展開において、BBUが信頼性の高い5Gネットワークの計算中枢として機能していることを裏付けています。
BBU主導のネットワークパフォーマンス:遅延の低減、スループットの拡大、および効率化
集中型RAN(C-RAN):BBUの仮想化による動的リソースプーリング
クラウドRANまたはC-RANの構成では、各セルサイトに個別の装置を設置する代わりに、複数のセルサイト向けに処理能力をプールする仮想ベースバンドユニットを使用します。これにより、従来見られた分散型のハードウェア構成が不要になり、運用コストをざっくり30%程度削減できます。また、リアルタイムで必要に応じてワークロードを動的に再配分することが可能になります。ネットワークトラフィックが急増した場合、システムは使用率が低い近隣のセルから余剰容量を動的に取得し、最も必要とされる場所へそのリソースを割り当てることができます。その結果、新しい機器を追加購入することなく、スループットが以前の約3倍まで向上します。考えると実に印象的です。
高度なBBU制御によるマッシブMIMO協調およびスペクトル再利用
高度なBBUアルゴリズムにより、数百個のアンテナ素子を協調制御し、正確なビームフォーミングと空間多重を実現します。これにより、複数のユーザーが同じ周波数帯域を同時に共有でき、スペクトル効率が47%向上します。また、信号を方向性を持って集中させることで干渉を最小限に抑え、99.999%の信頼性を維持しながらネットワーク密度を5倍に高めることが可能になります。これはミッションクリティカルなアプリケーションにとって極めて重要です。
主な影響 :
- 遅延低減:産業用IoT向けの10ms未満の応答
- スループット拡張:mmWave展開時におけるセルあたり40Gbps
- エネルギー効率:分散型RANと比較してギガバイトあたり60%低い消費電力
ベースバンドユニット性能を支える主要ハードウェア構成部品
FPGA/ASICアクセラレーション:従来のx86システムと比較したより高いFFTスループットの実現
フィールドプログラマブルゲートアレイ(FPGA)とアプリケーションスペシフィックインタグレーテッドサーキット(ASIC)は、5G信号をリアルタイムで処理するために必要な計算能力を提供し、従来のx86システムに比べてより高速な処理を実現するとともに、全体的なエネルギー消費を抑えることができます。これらの特殊用途向けチップは、今や至る所で見られる大規模MIMO構成において変調・復調を正しく行うために不可欠である、いわゆる高速フーリエ変換(FFT)計算のような、並列処理可能なタスクの処理を大幅に高速化します。企業が汎用CPUからFPGAまたはASICソリューションに移行することで、本質的にメインプロセッサから重い処理負荷を肩代わりする形になります。このアプローチにより、処理遅延が削減されると同時に、電力消費もかなり節約されます。ある研究では、都市部でこうした技術が導入された場合、消費電力が約3分の1からほぼ半分程度まで削減されることが示されています。
現代のBBU設計におけるプロセッサ、DSP、メモリ、およびインターフェースの統合
今日の基地局ユニット(BBU)は、非常に多くの機能を一つの筐体に凝縮しています。マルチコアプロセッサが専用のデジタル信号処理装置(DSP)とともに動作し、高速メモリや各種標準インターフェースがすべて1つのコンパクトなパッケージに統合されています。DSPは、信号の変調・復調や複雑なチャネル符号化処理といった、特に負荷の高い処理を主に担当します。一方、汎用プロセッサはネットワークスライシングや上位層のプロトコル処理などの管理を担っています。大量の無線周波数データを処理する際には、同期型DRAMがバッファとして活用され、200ギガビット/秒を超える速度に対応することで、通信トラフィックの急増時でも処理が滞らないようにしています。また、接続に関しては、これらすべてが円滑に連携するためにいくつか重要なインターフェースが関与しています。
- eCPRI :低遅延のフロントホール接続を実現します
- 25GbE :バックホール集約をサポートします
-
PCIe Gen4 :高速なチップ間通信を可能にします
この密に統合された設計により、バスの競合が排除され、極めて高い信頼性が求められるアプリケーション向けに、100µs以下の決定論的遅延を保証します。
基地局ベースバンドユニットの戦略的利点:スケーラビリティ、エネルギー効率、将来への対応
O-RANのトレードオフ:分散化とBBUのパフォーマンス一貫性の両立
Open RANの概念は、ソフトウェアとハードウェアを分離することで、より多くのベンダーが市場に参入することを促進し、革新を推進します。しかし、このアプローチは異なる機器間でベースバンドユニット(BBU)の性能を安定させようとする際に問題を引き起こします。モジュラー方式はスケーリングや拡張を容易にするだけでなく、昨年の『Telecom Efficiency Report』によれば、エネルギー消費を約30%削減できる利点もあります。しかし、これらのメリットには代償が伴います。システムはインターフェース仕様への厳密な準拠が必要であり、そうでなければ信号のタイミングばらつきやデータ転送速度の不整合といった問題が生じます。IoTデバイスを通じて接続された工場の自動化システムなど、ミリ秒単位の応答が重要なアプリケーションにおいては、ネットワーク事業者は最初から最後まですべてがシームレスに連携するよう確実にしなければなりません。BBUを戦略的に展開するということは、今後登場する5G-Advancedの厳しい性能要件、さらにはまだ定義されていない6Gの基準を満たすために必要なものと、オープンプラットフォームが提供する柔軟性との間で最適なバランスを見つけることを意味します。





